간간히 올라오는 AI그림들
이제는 AI 그림이라는 개념이 상식이 되어가는 분위기다.
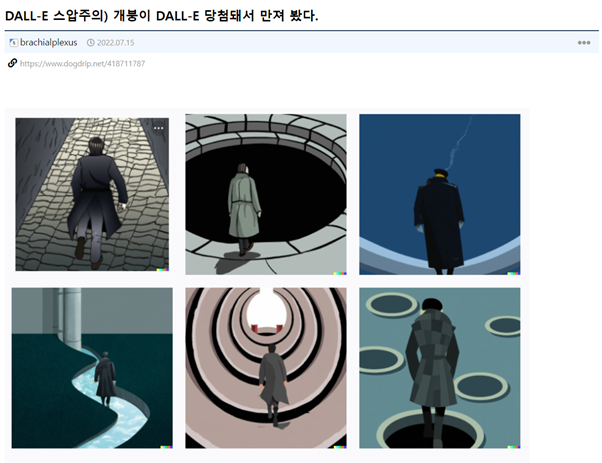
https://www.dogdrip.net/418711787
이 글을 쓴 게 작년 7월인데 새삼스럽다.
반년 사이에 얼마나 변했는지 알아보자
처음 시작은 DALL-E 2 였다.

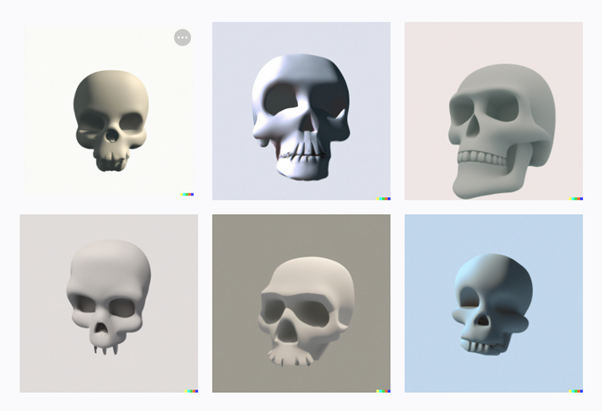

이 정도만 해도 혁명적이라고 말하던 시기가 있었다.
그 다음은 미드저니


Dall e 이후 한달 반 9월즈음 출시한 ai 모델이었다. 웅장한 분위기가 인상적인 모델로 유명했다.
그리고 지금 AI 그림 트렌드의 주축인 모델 stable diffusion



오픈소스라는 파격적인 방식으로 순식간에 다른 모델을 제치고 현재 AI 그림 커뮤니티에서 가장 많이 언급되는 모델이 되었다.
지금도 개드립에 간간히 올라오는 AI 그림들은 대부분 이 stable diffusion을 기반으로 하는 모델로 그렸다고 할 수 있다. Novel AI같은 것도 stable diffusion 기반으로 만들어졌다.
stable diffusion이 AI 그림계에서 중요할 수밖에 없는 이유
얘만 오픈소스라는 점이다.
덕분에 게임에 모드 깔듯이 너도 나도 튜닝을 할 수 있게 되었고,
임베딩, 하이퍼네트워크, 드림부스, LoRa 라는 튜닝방식이 등장하면서 이제 AI그림 관련 개념의 기반이 어느정도 다져졌다.
가볍게 그림으로 설명해보자

이게 지금까지 나온 유명한 AI 그림 모델이다. 니지저니는 미드저니 기반으로 만들어졌고,
novel ai는 stable diffusion 기반으로 만들어졌다. DALL-E는 다른 모델이다.
앞서 말했듯 오픈소스라는 강점이 있는 stable diffusion이 현재 매우 큰 점유율을 차지하고 있으며 매우 활발하게 모델의 개발과 공유가 이루어지고 있다.
사실 stable diffusion은 엄밀히는 그림만 그리는 AI는 아니고 프로그램 자체는 각종 AI 프로그램을 구동하는 오픈 소스 프로그램이다.
일반인들이 사용하기에는 어려웠기 때문에 이를 다루기 위한 Web UI가 만들어진다.
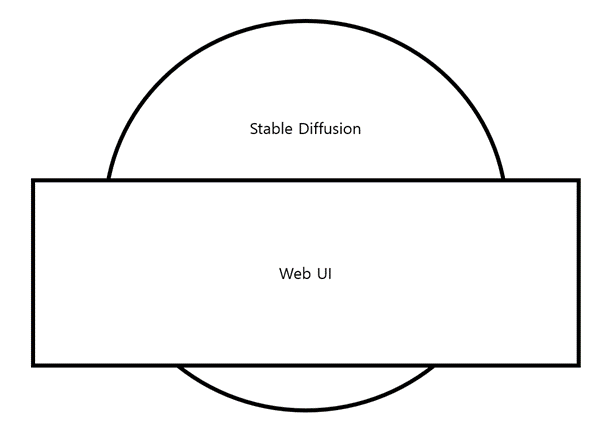
Web UI는 stable diffusion를 편리하게 다루기 위한 도구이며 사실상 stable diffusion과 횬용해서 많이 쓰인다.
Stable Diffusion의 가장 중요한 것은 모델 / 체크포인트 라고 불리어지는 학습 데이터이며, 이것을 어떤 것으로 갈아 끼우느냐에 따라 출력물이 매우 크게 변한다.
말하자면 Stable Diffusion/Web UI는 일종의 스팀 플랫폼이고, 모델 / 체크포인트는 게임이라고 생각하면 된다.
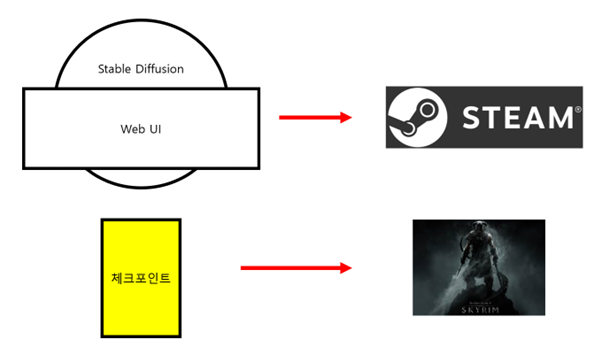
Web UI로 어떤 모델을 구동하냐에 따라 내용물이 달라지고 화풍, 스타일이 완전히 변할 수 있다.

초기에는 그림을 아무거나 막 학습한 모델을 썼었다. 마치 2012년에 출시한 스카이림 바닐라 버전을 돌리는 것처럼 말이다.

돌리는 사람의 목적, 취향, 원하는 스타일이 반영이 안되어 있기 때문에 원하는 결과물을 얻기 위해서 무지성 랜덤 돌리기를 해야했고 그래도 퀄리티가 썩 좋진 않았다.
팔이 3개라던지 허리가 없어지고 머리랑 다리가 합쳐졌다든지 같은 호러짤도 나왔다.
하지만 시간이 지나면서 모델도 점점 패치가 되고, 더 나은 버전이 나오기 시작한다

게다가 중간에 Novel AI의 소스코드가 긴빠이 당하는 사건이 일어나면서 양질의 데이터가 대량으로 들어오는 일이 있었다.
암튼 덕분에 모델의 성능은 더욱 좋아졌지만…
사람들은 여기서 만족하지 않았다.
버전이 올라갔다 한들, 모델의 결과물 수준은 아직 바닐라 스카이림의 감자 같은 NPC 얼굴처럼
보는 사람의 욕구를 전부 충족시켜주진 못했고
이를 만족하기 위해 튜닝, 즉 모드질을 하게 된다.
Stable Diffusion/Web UI의 모드질(튜닝)에는 크게 4가지 방식이 있다.
임베딩 / Embedding
하이퍼네트워크 / Hypernetwork
드림부스 / Dreambooth
로라 / LoRa / Lora
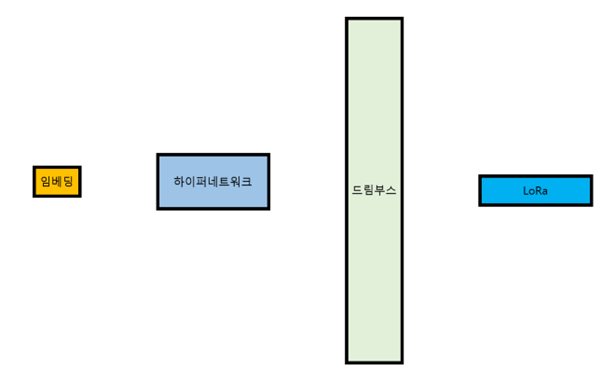
각각의 방식을 시각화하면 이렇다.
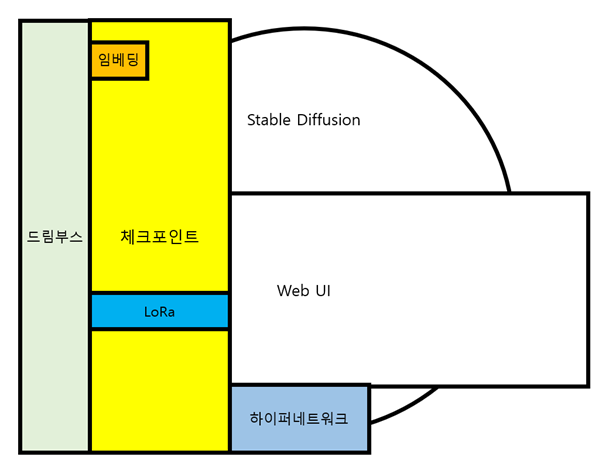
임베딩 / Embedding
임베딩 : 학습한 데이터를 하나의 프롬프트로 취급, 즉 단어를 학습시킴
만약 학습한 데이터가 금발벽안 소녀이고 이를 AI그림임베딩이라 명명한 후 프롬프트에 (AI그림임베딩)으로 입력하면 결과물에 금발벽안 소녀가 출력됨
KB 단위의 매우 적은 용량
하이퍼네트워크 / Hypernetwork
학습한 데이터를 결과물에 최대한 적용, 즉 그림체나 스타일을 학습시킴
최소 8gb 이상의 vram이 필요하고 사전 준비가 많이 필요함
용량이 크며 하이퍼네트워크 설정에서 갈아끼워줘야 적용됨
한번에 하나의 하이퍼네트워크만을 적용해야 했기 때문에 병합사용이 불가했으나 이후 업데이트로 지원됨
100~200MB 사이의 용량
드림부스 / Dreambooth
학습한 데이터를 스테이블 디퓨전에 새로 집어넣음. 즉 새로운 개념을 모델에 주입함
하이퍼네트워크 이상의 스펙이 필요해 지금은 런포드 같은 하이테크 하드웨어를 빌려서 사용함
모델로써 작동하기에 GB단위의 매우 큰 용량
로라 / LoRa / Lora
드림부스가 새로운 모델을 만드는 것이라면 로라는 기존 모델에 간섭하지 않고 레이어와 레이어 사이에 학습시킨 새로운 레이어를 추가하는 형태로 학습시키는 기술로 하이퍼네트워크와 임베딩의 상위호환급 취급을 받는 중
용량이 작음에도 큰 영향력을 발휘하는게 장점
100~200MB의 비교적 작은 용량
각각의 방식은 장단점이 존재하지만 그 중 LoRa는 임베딩, 하이퍼네트워크에 비해 장점이 뚜렷해서 요즘 튜닝 방식으로 급부상하는 중이다.

이런 모드질(튜닝) 덕분에 이제는 좀 더 사용자가 원하는 그림에 초점을 맞춰서 뽑을 수 있게 되었다.
아래는 사용한 LoRa와 결과물들이다.

Sans(와!) Lora
Sans만 뽑아준다.

엠버(원신) LoRa

One Piece (Wano Saga) Style LoRA
같은 캐릭터만 뽑아주는게 아니라 화풍을 따라할 수도 있다.


개미허리 Lora
뱃가죽이 등에 붙은 그림을 그려준다. 왜 이런게 있는지 이해가 안된다.
참고로 Lora 공유 사이트를 둘러보던 중 그 ‘카스’ Lora도 있는 걸 발견했다.


피규어 컨셉 LoRa
개인적으로 개쩌는거 같다.
이상 현재 Ai 그림 모델이 발전한 근황이다
'정보' 카테고리의 다른 글
| 삼성 스마트폰 잃어 버렸을때 기억해야할 꿀팁.jpg (0) | 2023.03.01 |
|---|---|
| 다크서클을 제거에 확실한 효과가 있는 영양 보충제 및 화장품 (0) | 2023.02.16 |
| MSM의 효능과 부작용 (0) | 2023.02.15 |
| 레딧에서 난리난 검열 풀린 ChatGPT(jailbreak) (0) | 2023.02.14 |
| 문학선생님이 직접 읽고 추천하는 책 목록 (0) | 2023.01.31 |
| 냉동볶음밥 구입 선택 가이드 (0) | 2023.01.29 |
| 성심당 빵 추천🥖🍞🥪🥯🥐 (0) | 2023.01.28 |
| 년도별 넷플릭스 최고 호평작들 (0) | 2023.01.28 |


댓글